Redux Fundamentals, Part 7: Standard Redux Patterns
- Standard patterns used in real-world Redux apps, and why those patterns exist:
- Action creators for encapsulating action objects
- Memoized selectors for improving performance
- Tracking request status via loading enums
- Normalizing state for managing collections of items
- Working with promises and thunks
- Understanding the topics in all previous sections
In Part 6: Async Logic and Data Fetching, we saw how to use Redux middleware to write async logic that can talk to the store. In particular, we used the Redux "thunk" middleware to write functions that can contain reusable async logic, without knowing what Redux store they'll be talking to ahead of time.
So far, we've covered the basics of how Redux actually works. However, real world Redux applications use some additional patterns on top of those basics.
It's important to note that none of these patterns are required to use Redux! But, there are very good reasons why each of these patterns exists, and you'll see some or all of them in almost every Redux codebase.
In this section, we'll rework our existing todo app code to use some of these patterns, and talk about why they're commonly used in Redux apps. Then, in Part 8, we'll talk about "modern Redux", including how to use our official Redux Toolkit package to simplify all the Redux logic we've written "by hand" in our app, and why we recommend using Redux Toolkit as the standard approach for writing Redux apps.
Note that this tutorial intentionally shows older-style Redux logic patterns that require more code than the "modern Redux" patterns with Redux Toolkit we teach as the right approach for building apps with Redux today, in order to explain the principles and concepts behind Redux. It's not meant to be a production-ready project.
See these pages to learn how to use "modern Redux" with Redux Toolkit:
- The full "Redux Essentials" tutorial, which teaches "how to use Redux, the right way" with Redux Toolkit for real-world apps. We recommend that all Redux learners should read the "Essentials" tutorial!
- Redux Fundamentals, Part 8: Modern Redux with Redux Toolkit, which shows how to convert the low-level examples from earlier sections into modern Redux Toolkit equivalents
Action Creators
In our app, we've been writing action objects directly in the code, where they're being dispatched:
dispatch({ type: 'todos/todoAdded', payload: trimmedText })
However, in practice, well-written Redux apps don't actually write those action objects inline when we dispatch them. Instead, we use "action creator" functions.
An action creator is a function that creates and returns an action object. We typically use these so we don't have to write the action object by hand every time:
const todoAdded = text => {
return {
type: 'todos/todoAdded',
payload: text
}
}
We then use them by calling the action creator, and then passing the resulting action object directly to dispatch:
store.dispatch(todoAdded('Buy milk'))
console.log(store.getState().todos)
// [ {id: 0, text: 'Buy milk', completed: false}]
Detailed Explanation: Why use Action Creators?
In our small example todo app, writing action objects by hand every time isn't too difficult. In fact, by switching to using action creators, we've added more work - now we have to write a function and the action object.
But, what if we needed to dispatch the same action from many parts of the application? Or what if there's some additional logic that we have to do every time we dispatch an action, like creating a unique ID? We'd end up having to copy-paste the additional setup logic every time we need to dispatch that action.
Action creators have two primary purposes:
- They prepare and format the contents of action objects
- They encapsulate any additional work needed whenever we create those actions
That way, we have a consistent approach for creating actions, whether or not there's any extra work that needs to be done. The same goes for thunks as well.
Using Action Creators
Let's update our todos slice file to use action creators for a couple of our action types.
We'll start with the two main actions we've been using so far: loading the list of todos from the server, and adding a new todo after saving it to the server.
Right now, todosSlice.js is dispatching an action object directly, like this:
dispatch({ type: 'todos/todosLoaded', payload: response.todos })
We'll create a function that creates and returns that same kind of action object, but accepts the array of todos as its argument and puts it into the action as action.payload. Then, we can dispatch the action using that new action creator inside of our fetchTodos thunk:
export const todosLoaded = todos => {
return {
type: 'todos/todosLoaded',
payload: todos
}
}
export async function fetchTodos(dispatch, getState) {
const response = await client.get('/fakeApi/todos')
dispatch(todosLoaded(response.todos))
}
We can also do the same thing for the "todo added" action:
export const todoAdded = todo => {
return {
type: 'todos/todoAdded',
payload: todo
}
}
export function saveNewTodo(text) {
return async function saveNewTodoThunk(dispatch, getState) {
const initialTodo = { text }
const response = await client.post('/fakeApi/todos', { todo: initialTodo })
dispatch(todoAdded(response.todo))
}
}
While we're at it, let's do the same thing for the "color filter changed" action:
export const colorFilterChanged = (color, changeType) => {
return {
type: 'filters/colorFilterChanged',
payload: { color, changeType }
}
}
And since this action was being dispatched from the <Footer> component, we'll need to import the colorFilterChanged action creator over there and use it:
import React from 'react'
import { useSelector, useDispatch } from 'react-redux'
import { availableColors, capitalize } from '../filters/colors'
import { StatusFilters, colorFilterChanged } from '../filters/filtersSlice'
// omit child components
const Footer = () => {
const dispatch = useDispatch()
const todosRemaining = useSelector(state => {
const uncompletedTodos = state.todos.filter(todo => !todo.completed)
return uncompletedTodos.length
})
const { status, colors } = useSelector(state => state.filters)
const onMarkCompletedClicked = () => dispatch({ type: 'todos/allCompleted' })
const onClearCompletedClicked = () =>
dispatch({ type: 'todos/completedCleared' })
const onColorChange = (color, changeType) =>
dispatch(colorFilterChanged(color, changeType))
const onStatusChange = status =>
dispatch({ type: 'filters/statusFilterChanged', payload: status })
// omit rendering output
}
export default Footer
Notice that the colorFilterChanged action creator actually accepts two different arguments, and then combines them together to form the right action.payload field.
This doesn't change anything about how the application works, or how the Redux data flow behaves - we're still creating action objects, and dispatching them. But, instead of writing action objects directly in our code all the time, we're now using action creators to prepare those action objects before they're dispatched.
We can also use action creators with thunk functions, and in fact we wrapped a thunk in an action creator in the previous section . We specifically wrapped saveNewTodo in a "thunk action creator" function so that we could pass in a text parameter. While fetchTodos doesn't take any parameters, we could still wrap it in an action creator as well:
export function fetchTodos() {
return async function fetchTodosThunk(dispatch, getState) {
const response = await client.get('/fakeApi/todos')
dispatch(todosLoaded(response.todos))
}
}
And that means we have to change the place it's dispatched in index.js to call the outer thunk action creator function, and pass the returned inner thunk function to dispatch:
import store from './store'
import { fetchTodos } from './features/todos/todosSlice'
store.dispatch(fetchTodos())
We've written thunks using the function keyword so far to make it clear what they're doing. However, we can also write them using arrow function syntax instead. Using implicit returns can shorten the code, although it may make it a bit harder to read as well if you're not familiar with arrow functions:
// Same thing as the above example!
export const fetchTodos = () => async dispatch => {
const response = await client.get('/fakeApi/todos')
dispatch(todosLoaded(response.todos))
}
Similarly, we could shorten the plain action creators if we wanted to:
export const todoAdded = todo => ({ type: 'todos/todoAdded', payload: todo })
It's up to you to decide whether using arrow functions this way is better or not.
For more details on why action creators are useful, see:
Memoized Selectors
We've already seen that we can write "selector" functions, which accept the Redux state object as an argument, and return a value:
const selectTodos = state => state.todos
What if we need to derive some data? For example, maybe we want to have an array of only the todo IDs:
const selectTodoIds = state => state.todos.map(todo => todo.id)
However, array.map() always returns a new array reference. We know that the React-Redux useSelector hook will re-run its selector function after every dispatched action, and if the selector result changes, it will force the component to re-render.
In this example, calling useSelector(selectTodoIds) will always cause the component to re-render after every action, because it's returning a new array reference!
In Part 5, we saw that we can pass shallowEqual as an argument to useSelector. There's another option here, though: we could use "memoized" selectors.
Memoization is a kind of caching - specifically, saving the results of an expensive calculation, and reusing those results if we see the same inputs later.
Memoized selector functions are selectors that save the most recent result value, and if you call them multiple times with the same inputs, will return the same result value. If you call them with different inputs than last time, they will recalculate a new result value, cache it, and return the new result.
Memoizing Selectors with createSelector
The Reselect library provides a createSelector API that will generate memoized selector functions. createSelector accepts one or more "input selector" functions as arguments, plus an "output selector", and returns the new selector function. Every time you call the selector:
- All "input selectors" are called with all of the arguments
- If any of the input selector return values have changed, the "output selector" will re-run
- All of the input selector results become arguments to the output selector
- The final result of the output selector is cached for next time
Let's create a memoized version of selectTodoIds and use that with our <TodoList>.
First, we need to install Reselect:
npm install reselect
Then, we can import and call createSelector. Our original selectTodoIds function was defined over in TodoList.js, but it's more common for selector functions to be written in the relevant slice file. So, let's add this to the todos slice:
import { createSelector } from 'reselect'
// omit reducer
// omit action creators
export const selectTodoIds = createSelector(
// First, pass one or more "input selector" functions:
state => state.todos,
// Then, an "output selector" that receives all the input results as arguments
// and returns a final result value
todos => todos.map(todo => todo.id)
)
Then, let's use it in <TodoList>:
import React from 'react'
import { useSelector, shallowEqual } from 'react-redux'
import { selectTodoIds } from './todosSlice'
import TodoListItem from './TodoListItem'
const TodoList = () => {
const todoIds = useSelector(selectTodoIds)
const renderedListItems = todoIds.map(todoId => {
return <TodoListItem key={todoId} id={todoId} />
})
return <ul className="todo-list">{renderedListItems}</ul>
}
This actually behaves a bit differently than the shallowEqual comparison function does. Any time the state.todos array changes, we're going to create a new todo IDs array as a result. That includes any immutable updates to todo items like toggling their completed field, since we have to create a new array for the immutable update.
Memoized selectors are only helpful when you actually derive additional values from the original data. If you are only looking up and returning an existing value, you can keep the selector as a plain function.
Selectors with Multiple Arguments
Our todo app is supposed to have the ability to filter the visible todos based on their completed status. Let's write a memoized selector that returns that filtered list of todos.
We know we need the entire todos array as one argument to our output selector. We also need to pass in the current completion status filter value as well. We'll add a separate "input selector" to extract each value, and pass the results to the "output selector".
import { createSelector } from 'reselect'
import { StatusFilters } from '../filters/filtersSlice'
// omit other code
export const selectFilteredTodos = createSelector(
// First input selector: all todos
state => state.todos,
// Second input selector: current status filter
state => state.filters.status,
// Output selector: receives both values
(todos, status) => {
if (status === StatusFilters.All) {
return todos
}
const completedStatus = status === StatusFilters.Completed
// Return either active or completed todos based on filter
return todos.filter(todo => todo.completed === completedStatus)
}
)
Note that we've now added an import dependency between two slices - the todosSlice is importing a value from the filtersSlice. This is legal, but be careful. If two slices both try to import something from each other, you can end up with a "cyclic import dependency" problem that can cause your code to crash. If that happens, try moving some common code to its own file and import from that file instead.
Now we can use this new "filtered todos" selector as an input to another selector that returns the IDs of those todos:
export const selectFilteredTodoIds = createSelector(
// Pass our other memoized selector as an input
selectFilteredTodos,
// And derive data in the output selector
filteredTodos => filteredTodos.map(todo => todo.id)
)
If we switch <TodoList> to use selectFilteredTodoIds, we should then be able to mark a couple todo items as completed:
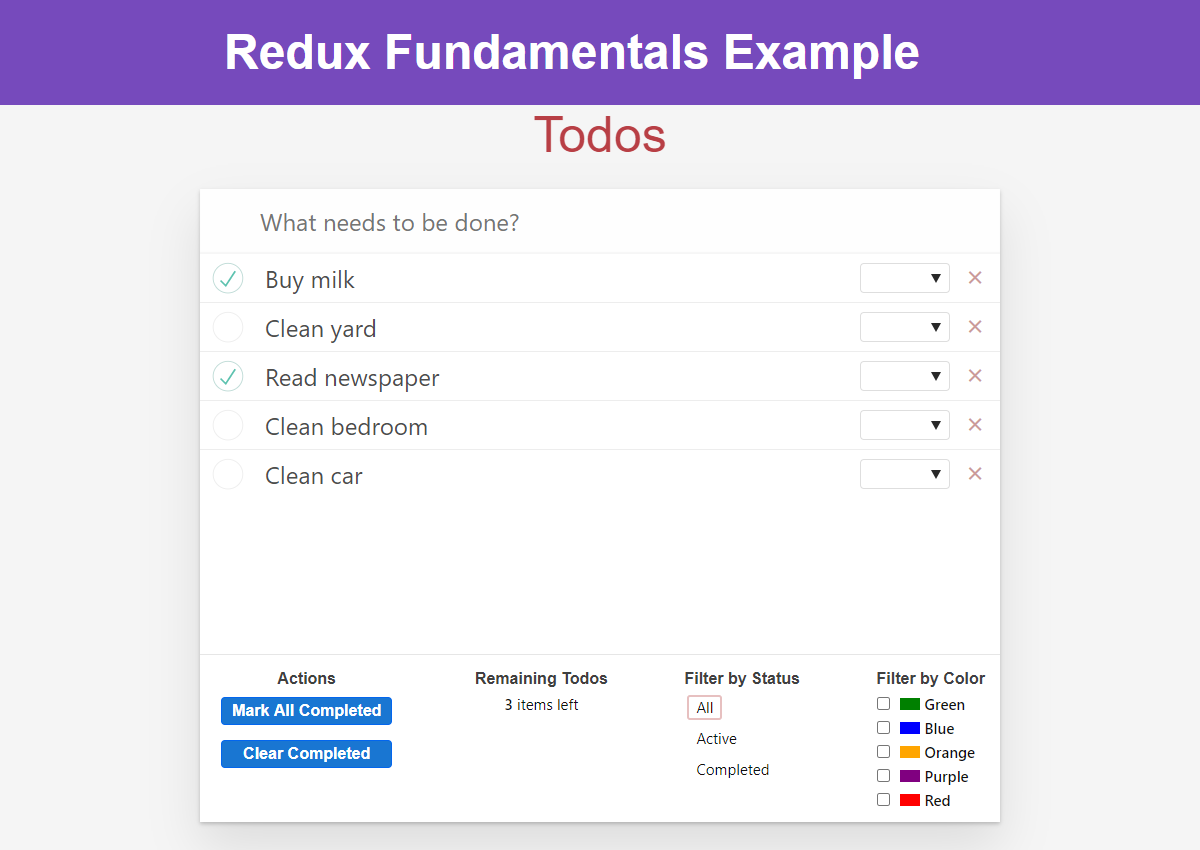
and then filter the list to only show completed todos:
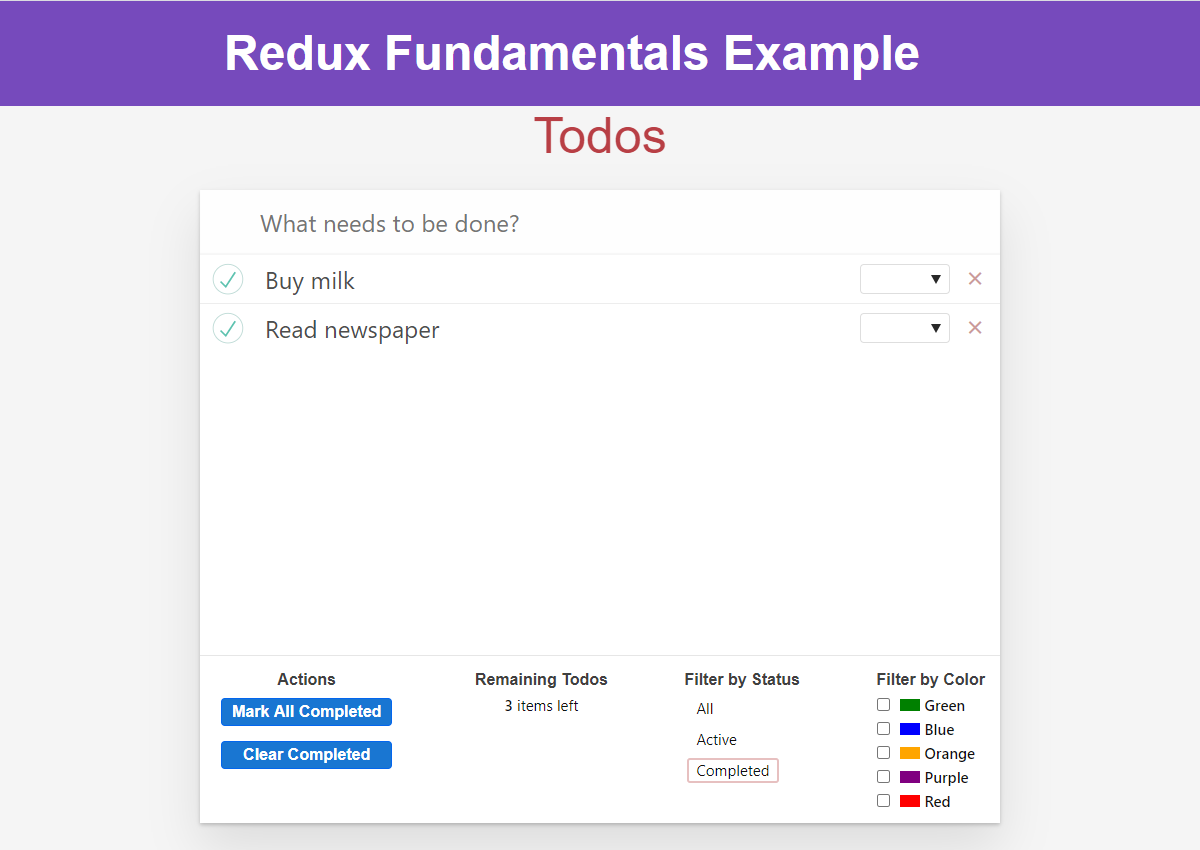
We can then expand our selectFilteredTodos to also include color filtering in the selection as well:
export const selectFilteredTodos = createSelector(
// First input selector: all todos
selectTodos,
// Second input selector: all filter values
state => state.filters,
// Output selector: receives both values
(todos, filters) => {
const { status, colors } = filters
const showAllCompletions = status === StatusFilters.All
if (showAllCompletions && colors.length === 0) {
return todos
}
const completedStatus = status === StatusFilters.Completed
// Return either active or completed todos based on filter
return todos.filter(todo => {
const statusMatches =
showAllCompletions || todo.completed === completedStatus
const colorMatches = colors.length === 0 || colors.includes(todo.color)
return statusMatches && colorMatches
})
}
)
Notice that by encapsulating the logic in this selector, our component never needed to change, even as we changed the filtering behavior. Now we can filter by both status and color at once:
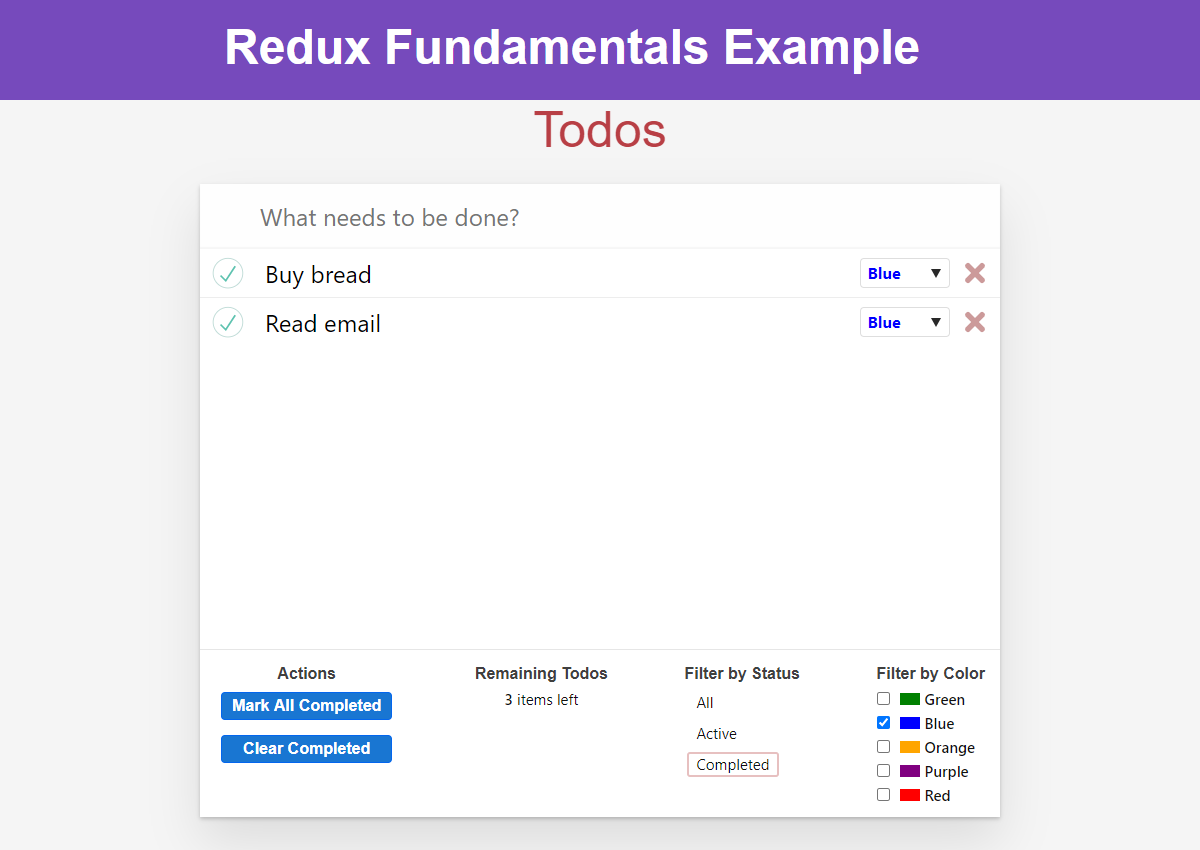
Finally, we've got several places where our code is looking up state.todos. We're going to be making some changes to how that state is designed as we go through the rest of this section, so we'll extract a single selectTodos selector and use that everywhere. We can also move selectTodoById over into the todosSlice:
export const selectTodos = state => state.todos
export const selectTodoById = (state, todoId) => {
return selectTodos(state).find(todo => todo.id === todoId)
}
For more details on why we use selector functions and how to write memoized selectors with Reselect, see:
Async Request Status
We're using an async thunk to fetch the initial list of todos from the server. Since we're using a fake server API, that response comes back immediately. In a real app, the API call might take a while to resolve. In that case, it's common to show some kind of a loading spinner while we wait for the response to complete.
This is usually handled in Redux apps by:
- Having some kind of "loading state" value to indicate the current status of a request
- Dispatching a "request started" action before making the API call, which is handled by changing the loading state value
- Updating the loading state value again when the request completes to indicate that the call is done
The UI layer then shows a loading spinner while the request is in progress, and switches to showing the actual data when the request is complete.
We're going to update our todos slice to track a loading state value, and dispatch an additional 'todos/todosLoading' action as part of the fetchTodos thunk.
Right now, the state of our todos reducer is only the array of todos itself. If we want to track the loading state inside the todos slice, we'll need to reorganize the todos state to be an object that has the todos array and the loading state value. That also means rewriting the reducer logic to handle the additional nesting:
const initialState = {
status: 'idle',
entities: []
}
export default function todosReducer(state = initialState, action) {
switch (action.type) {
case 'todos/todoAdded': {
return {
...state,
entities: [...state.entities, action.payload]
}
}
case 'todos/todoToggled': {
return {
...state,
entities: state.entities.map(todo => {
if (todo.id !== action.payload) {
return todo
}
return {
...todo,
completed: !todo.completed
}
})
}
}
// omit other cases
default:
return state
}
}
// omit action creators
export const selectTodos = state => state.todos.entities
There's a few important things to note here:
- The todos array is now nested as
state.entitiesin thetodosReducerstate object. The word "entities" is a term that means "unique items with an ID", which does describe our todo objects. - That also means the array is nested in the entire Redux state object as
state.todos.entities - We now have to do extra steps in the reducer to copy the additional level of nesting for correct immutable updates, such as
stateobject ->entitiesarray ->todoobject - Because the rest of our code is only accessing the todos state via selectors, we only need to update the
selectTodosselector - the rest of the UI will continue to work as expected even though we reshaped our state considerably.
Loading State Enum Values
You'll also notice that we've defined the loading state field as a string enum:
{
status: 'idle' // or: 'loading', 'succeeded', 'failed'
}
instead of an isLoading boolean.
A boolean limits us to two possibilities: "loading" or "not loading". In reality, it's possible for a request to actually be in many different states, such as:
- Hasn't started at all
- In progress
- Succeeded
- Failed
- Succeeded, but now back in a situation where we might want to refetch
It's also possible that the app logic should only transition between specific states based on certain actions, and this is harder to implement using booleans.
Because of this, we recommend storing loading state as a string enum value instead of boolean flags.
For a detailed explanation of why loading states should be enums, see:
Based on that, we'll add a new "loading" action that will set our status to 'loading', and update the "loaded" action to reset the state flag to 'idle':
const initialState = {
status: 'idle',
entities: []
}
export default function todosReducer(state = initialState, action) {
switch (action.type) {
// omit other cases
case 'todos/todosLoading': {
return {
...state,
status: 'loading'
}
}
case 'todos/todosLoaded': {
return {
...state,
status: 'idle',
entities: action.payload
}
}
default:
return state
}
}
// omit action creators
// Thunk function
export const fetchTodos = () => async dispatch => {
dispatch(todosLoading())
const response = await client.get('/fakeApi/todos')
dispatch(todosLoaded(response.todos))
}
However, before we try to show this in the UI, we need to modify the fake server API to add an artificial delay to our API calls. Open up src/api/server.js, and look for this commented-out line around line 63:
new Server({
routes() {
this.namespace = 'fakeApi'
// this.timing = 2000
// omit other code
}
})
If you uncomment that line, the fake server will add a 2-second delay to every API call our app makes, which gives us enough time to actually see a loading spinner being displayed.
Now, we can read the loading state value in our <TodoList> component, and show a loading spinner instead based on that value.
// omit imports
const TodoList = () => {
const todoIds = useSelector(selectFilteredTodoIds)
const loadingStatus = useSelector(state => state.todos.status)
if (loadingStatus === 'loading') {
return (
<div className="todo-list">
<div className="loader" />
</div>
)
}
const renderedListItems = todoIds.map(todoId => {
return <TodoListItem key={todoId} id={todoId} />
})
return <ul className="todo-list">{renderedListItems}</ul>
}
In a real app, we'd also want to handle API failure errors and other potential cases.
Here's what the app looks like with that loading status enabled (to see the spinner again, reload the app preview or open it in a new tab):
Flux Standard Actions
The Redux store itself does not actually care what fields you put into your action object. It only cares that action.type exists and is a string. That means that you could put any other fields into the action that you want. Maybe we could have action.todo for a "todo added" action, or action.color, and so on.
However, if every action uses different field names for its data fields, it can be hard to know ahead of time what fields you need to handle in each reducer.
That's why the Redux community came up with the "Flux Standard Actions" convention, or "FSA". This is a suggested approach for how to organize fields inside of action objects, so that developers always know what fields contain what kind of data. The FSA pattern is widely used in the Redux community, and in fact you've already been using it throughout this whole tutorial.
The FSA convention says that:
- If your action object has any actual data, that "data" value of your action should always go in
action.payload - An action may also have an
action.metafield with extra descriptive data - An action may have an
action.errorfield with error information
So, all Redux actions MUST:
- be a plain JavaScript object
- have a
typefield
And if you write your actions using the FSA pattern, an action MAY
- have a
payloadfield - have an
errorfield - have a
metafield
Detailed Explanation: FSAs and Errors
The FSA specification says that:
The optional
errorproperty MAY be set totrueif the action represents an error. An action whoseerroris true is analogous to a rejected Promise. By convention, thepayloadSHOULD be an error object. Iferrorhas any other value besidestrue, includingundefinedandnull, the action MUST NOT be interpreted as an error.
The FSA specs also argue against having specific action types for things like "loading succeeded" and "loading failed".
However, in practice, the Redux community has ignored the idea of using action.error as a boolean flag, and instead settled on separate action types, like 'todos/todosLoadingSucceeded' and 'todos/todosLoadingFailed'. This is because it's much easier to check for those action types than it is to first handle 'todos/todosLoaded' and then check if (action.error).
You can do whichever approach works better for you, but most apps use separate action types for success and failure.
Normalized State
So far, we've kept our todos in an array. This is reasonable, because we received the data from the server as an array, and we also need to loop over the todos to show them as a list in the UI.
However, in larger Redux apps, it is common to store data in a normalized state structure. "Normalization" means:
- Making sure there is only one copy of each piece of data
- Storing items in a way that allows directly finding items by ID
- Referring to other items based on IDs, instead of copying the entire item
For example, in a blogging application, you might have Post objects that point to User and Comment objects. There might be many posts by the same person, so if every Post object includes an entire User, we would have many copies of the same User object. Instead, a Post object would have a user ID value as post.user, and then we could look up User objects by ID as state.users[post.user].
This means we typically organize our data as objects instead of arrays, where the item IDs are the keys and the items themselves are the values, like this:
const rootState = {
todos: {
status: 'idle',
entities: {
2: { id: 2, text: 'Buy milk', completed: false },
7: { id: 7, text: 'Clean room', completed: true }
}
}
}
Let's convert our todos slice to store the todos in a normalized form. This will require some significant changes to our reducer logic, as well as updating the selectors:
const initialState = {
status: 'idle',
entities: {}
}
export default function todosReducer(state = initialState, action) {
switch (action.type) {
case 'todos/todoAdded': {
const todo = action.payload
return {
...state,
entities: {
...state.entities,
[todo.id]: todo
}
}
}
case 'todos/todoToggled': {
const todoId = action.payload
const todo = state.entities[todoId]
return {
...state,
entities: {
...state.entities,
[todoId]: {
...todo,
completed: !todo.completed
}
}
}
}
case 'todos/colorSelected': {
const { color, todoId } = action.payload
const todo = state.entities[todoId]
return {
...state,
entities: {
...state.entities,
[todoId]: {
...todo,
color
}
}
}
}
case 'todos/todoDeleted': {
const newEntities = { ...state.entities }
delete newEntities[action.payload]
return {
...state,
entities: newEntities
}
}
case 'todos/allCompleted': {
const newEntities = { ...state.entities }
Object.values(newEntities).forEach(todo => {
newEntities[todo.id] = {
...todo,
completed: true
}
})
return {
...state,
entities: newEntities
}
}
case 'todos/completedCleared': {
const newEntities = { ...state.entities }
Object.values(newEntities).forEach(todo => {
if (todo.completed) {
delete newEntities[todo.id]
}
})
return {
...state,
entities: newEntities
}
}
case 'todos/todosLoading': {
return {
...state,
status: 'loading'
}
}
case 'todos/todosLoaded': {
const newEntities = {}
action.payload.forEach(todo => {
newEntities[todo.id] = todo
})
return {
...state,
status: 'idle',
entities: newEntities
}
}
default:
return state
}
}
// omit action creators
const selectTodoEntities = state => state.todos.entities
export const selectTodos = createSelector(selectTodoEntities, entities =>
Object.values(entities)
)
export const selectTodoById = (state, todoId) => {
return selectTodoEntities(state)[todoId]
}
Because our state.entities field is now an object instead of an array, we have to use nested object spread operators to update the data instead of array operations. Also, we can't loop over objects the way we loop over arrays, so there's several places where we have to use Object.values(entities) to get an array of the todo items so that we can loop over them.
The good news is that because we're using selectors to encapsulate the state lookups, our UI still doesn't have to change. The bad news is that the reducer code is actually longer and more complicated.
Part of the issue here is that this todo app example is not a large real-world application. So, normalizing state is not as useful in this particular app, and it's harder to see the potential benefits.
Fortunately, in Part 8: Modern Redux with Redux Toolkit we'll see some ways to drastically shorten the reducer logic for managing our normalized state.
For now, the important things to understand are:
- Normalization is commonly used in Redux apps
- The primary benefits are being able to look up individual items by ID and ensure that only one copy of an item exists in the state
For more details on why normalization is useful with Redux, see:
Thunks and Promises
We have one last pattern to look at for this section. We've already seen how to handle loading state in the Redux store based on dispatched actions. What if we need to look at the results of a thunk in our components?
Whenever you call store.dispatch(action), dispatch will actually return the action as its result. Middleware can then modify that behavior and return some other value instead.
We've already seen that the Redux Thunk middleware lets us pass a function to dispatch, calls the function, and then returns the result:
const reduxThunkMiddleware = storeAPI => next => action => {
// If the "action" is actually a function instead...
if (typeof action === 'function') {
// then call the function and pass `dispatch` and `getState` as arguments
// Also, return whatever the thunk function returns
return action(storeAPI.dispatch, storeAPI.getState)
}
// Otherwise, it's a normal action - send it onwards
return next(action)
}
This means that we can write thunk functions that return a promise, and wait on that promise in our components.
We already have our <Header> component dispatching a thunk to save new todo entries to the server. Let's add some loading state inside the <Header> component, then disable the text input and show another loading spinner while we're waiting for the server:
const Header = () => {
const [text, setText] = useState('')
const [status, setStatus] = useState('idle')
const dispatch = useDispatch()
const handleChange = e => setText(e.target.value)
const handleKeyDown = async e => {
// If the user pressed the Enter key:
const trimmedText = text.trim()
if (e.which === 13 && trimmedText) {
// Create and dispatch the thunk function itself
setStatus('loading')
// Wait for the promise returned by saveNewTodo
await dispatch(saveNewTodo(trimmedText))
// And clear out the text input
setText('')
setStatus('idle')
}
}
let isLoading = status === 'loading'
let placeholder = isLoading ? '' : 'What needs to be done?'
let loader = isLoading ? <div className="loader" /> : null
return (
<header className="header">
<input
className="new-todo"
placeholder={placeholder}
autoFocus={true}
value={text}
onChange={handleChange}
onKeyDown={handleKeyDown}
disabled={isLoading}
/>
{loader}
</header>
)
}
export default Header
Now, if we add a todo, we'll see a spinner in the header:
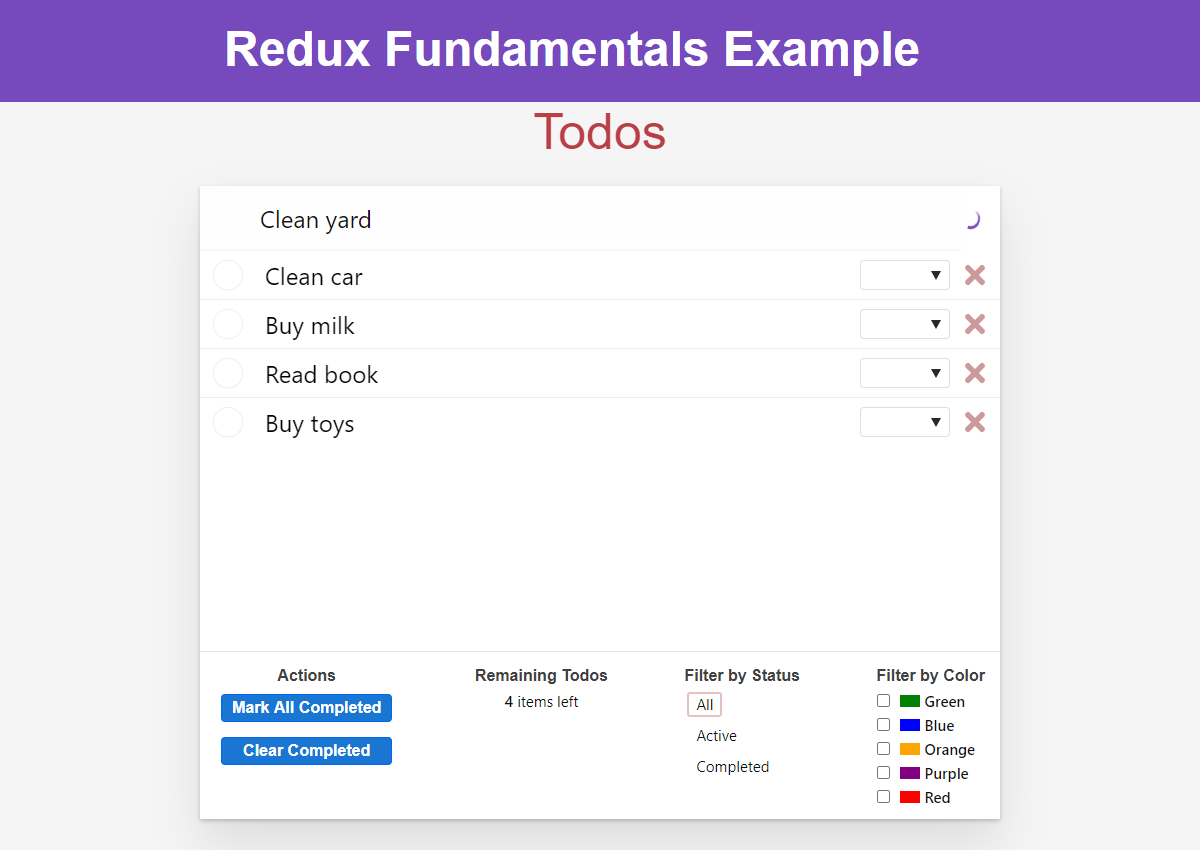
What You've Learned
As you've seen, there's several additional patterns that are widely used in Redux apps. These patterns are not required, and may involve writing more code initially, but they provide benefits like making logic reusable, encapsulating implementation details, improving app performance, and making it easier to look up data.
For more details on why these patterns exist and how Redux is meant to be used, see:
Here's how our app looks after it's been fully converted to use these patterns:
- Action creator functions encapsulate preparing action objects and thunks
- Action creators can accept arguments and contain setup logic, and return the final action object or thunk function
- Memoized selectors help improve Redux app performance
- Reselect has a
createSelectorAPI that generates memoized selectors - Memoized selectors return the same result reference if given the same inputs
- Reselect has a
- Request status should be stored as an enum, not booleans
- Using enums like
'idle'and'loading'helps track status consistently
- Using enums like
- "Flux Standard Actions" are the common convention for organizing action objects
- Actions use
payloadfor data,metafor extra descriptions, anderrorfor errors
- Actions use
- Normalized state makes it easier to find items by ID
- Normalized data is stored in objects instead of arrays, with item IDs as keys
- Thunks can return promises from
dispatch- Components can wait for async thunks to complete, then do more work
What's Next?
Writing all this code "by hand" can be time-consuming and difficult. That's why we recommend that you use our official Redux Toolkit package to write your Redux logic instead.
Redux Toolkit includes APIs that help you write all the typical Redux usage patterns, but with less code. It also helps prevent common mistakes like accidentally mutating state.
In Part 8: Modern Redux, we'll cover how to use Redux Toolkit to simplify all the code we've written so far.